Python正则替换时expected string or bytes-like object, got ‘Tag’
小编尝试通过Python爬取Discuz帖子内容,并解析其中的图片资源,将资源转换为简单的图片链接。
Discuz帖子本身的图片元素HTML结构:
<ignore_js_op>
<div style="text-align:center;"><img aid="3" class="zoom" file="data/attachment/forum/202005/12/231533jawu22vzwwzax9us.jpg" id="aimg_3" inpost="1" onclick="zoom(this, this.src, 0, 0, 0)" onmouseover="showMenu({'ctrlid':this.id,'pos':'12'})" src="static/image/common/none.gif" width="374" zoomfile="data/attachment/forum/202005/12/231533jawu22vzwwzax9us.jpg"/></div>
<div class="tip tip_4 aimg_tip" disautofocus="true" id="aimg_3_menu" style="position: absolute; display: none">
<div class="xs0">
<p><strong>2020051203.jpg</strong> <em class="xg1">(38.41 KB, 下载次数: 115)</em></p>
<p>
<a href="https://www.5izixue.com/forum.php?mod=attachment&aid=M3xhOTk2MjE5ZXwxNzI4ODA0Njc2fDB8Mg%3D%3D&nothumb=yes" target="_blank">下载附件</a>
</p>
<p>Outlook数据文件压缩方法 压缩数据</p>
<p class="xg1 y">2020-5-12 23:15 上传</p>
</div>
<div class="tip_horn"></div>
</div>
</ignore_js_op>为了实现以上需求,通过BeautifulSoup获取帖子完整内容,并通过Re正则表达式识别ignor_js_op标签,并替换为简单的img图片链接。
匹配和替换代码:
pattern = re.compile(r'<ignore_js_op>(.*?)</ignore_js_op>') new_html_content = re.sub(pattern, 'https://example.com/image.png', content_all.string) 替换后出现下图所示报警:TypeError: expected string or bytes-like object, got 'Tag'
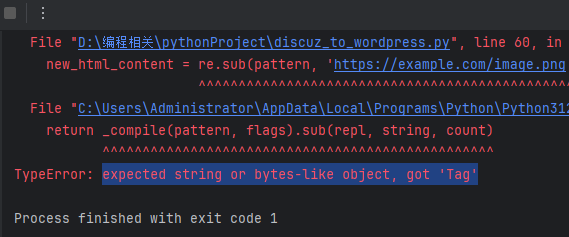
原因分析:以上报错,意味着你在程序中给方法或函数传了一个对象,但实际这个方法或函数是不支持对象的,需要传字符串或类似字节(bytes-like)。
解决方法:soup.find查找到的内容是对象,并不是字符串,不可以直接传给正则方法替换。可以使用soup对象的string属性,获取字符串内容,然后进行正则替换。
以上代码修改为下方代码后,执行程序报警消失!
new_html_content = re.sub(pattern, 'https://example.com/image.png', str((content_all.string)))
![Python Selenium调试出现 [WinError 193] %1 不是有效的 Win32 应用程序](https://www.5izixue.com/data/attachment/forum/202302/26/210533a8p0yi28xzu5rkis.jpg)